New AI models in Sequencer
We’ve broadened the set of AI engines you can pick from inside Sequencer. This update introduces a new Amazon Bedrock provider and a range of fresh models. Now you have more options to match a model to a real-world legal or business task - from fast, high-volume tagging to deep, long-document reasoning, and to weave those capabilities directly into your automated processes.
What’s new in the AWS Bedrock actor
We’ve added OpenAI as a Bedrock provider and extended our models to suit different workloads and price/performance profiles.
You can now pick from:
- Claude 3.7 Sonnet: excels at long-context reasoning and structured summaries; useful for processing long contracts and multi-document bundles where context across pages matters.
- OpenAI: gpt-oss-20b and gpt-oss-120b: open-source style models accessible through AWS Bedrock actor for teams that want the particular trade-offs of these OSS-weighted models.
These Bedrock options let teams balance throughput and nuance: use Sonnet or gpt-oss-120b where context and structure are primary concerns; pick gpt-oss-20b for lower-cost, high-volume steps.
What’s new in the OpenAI: GPT actor
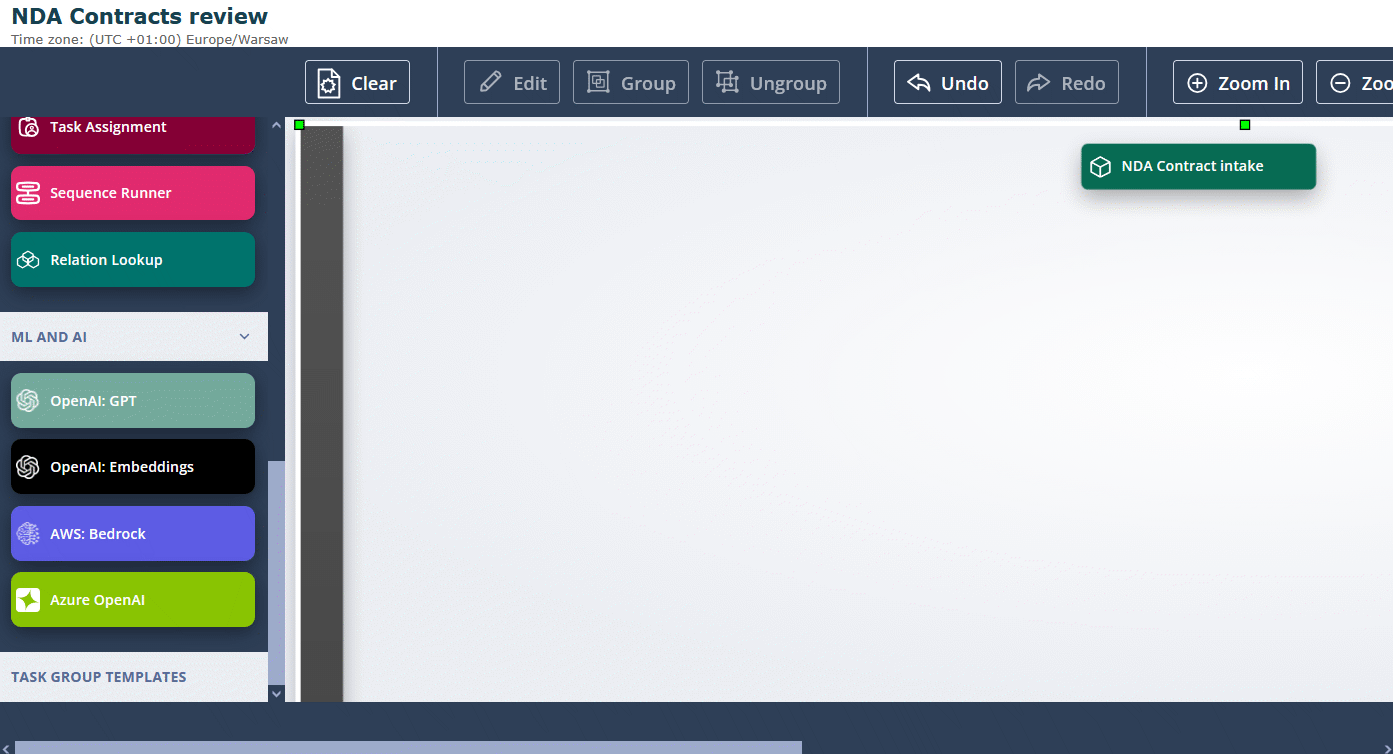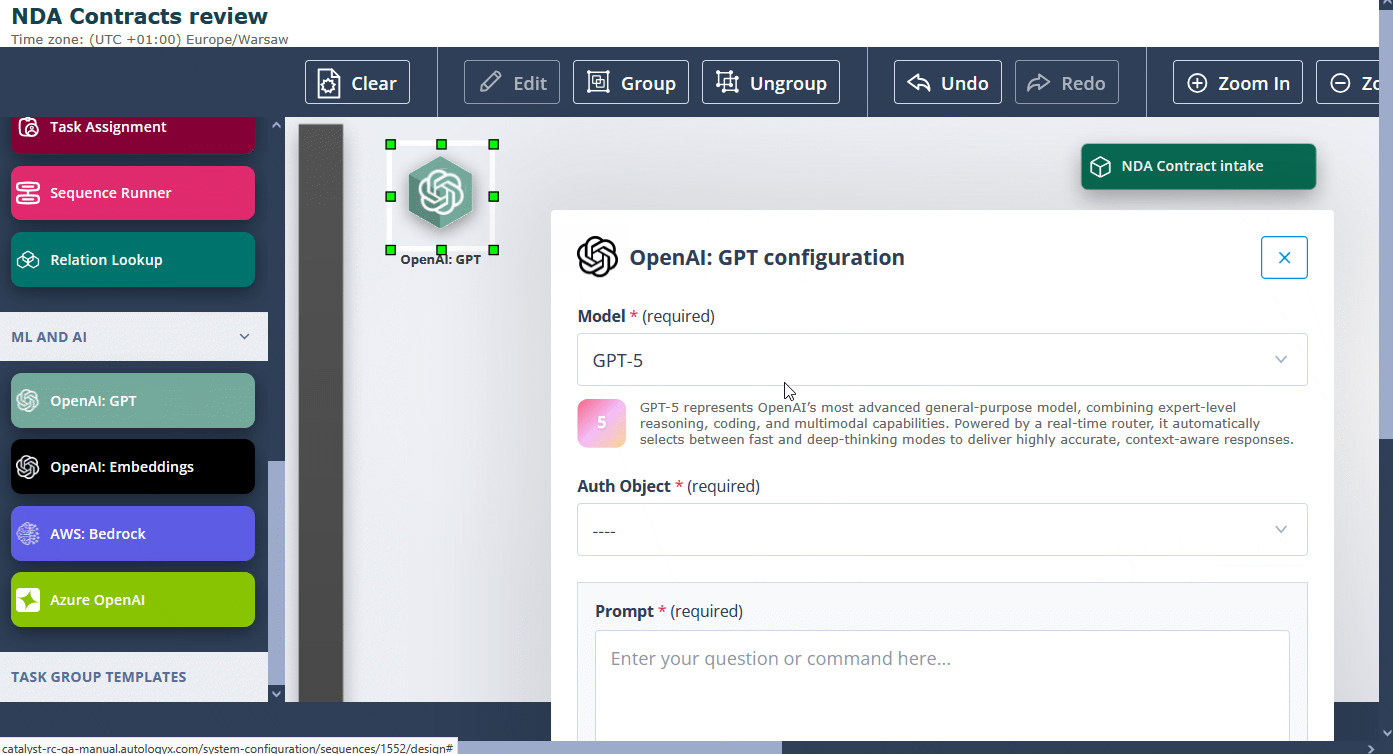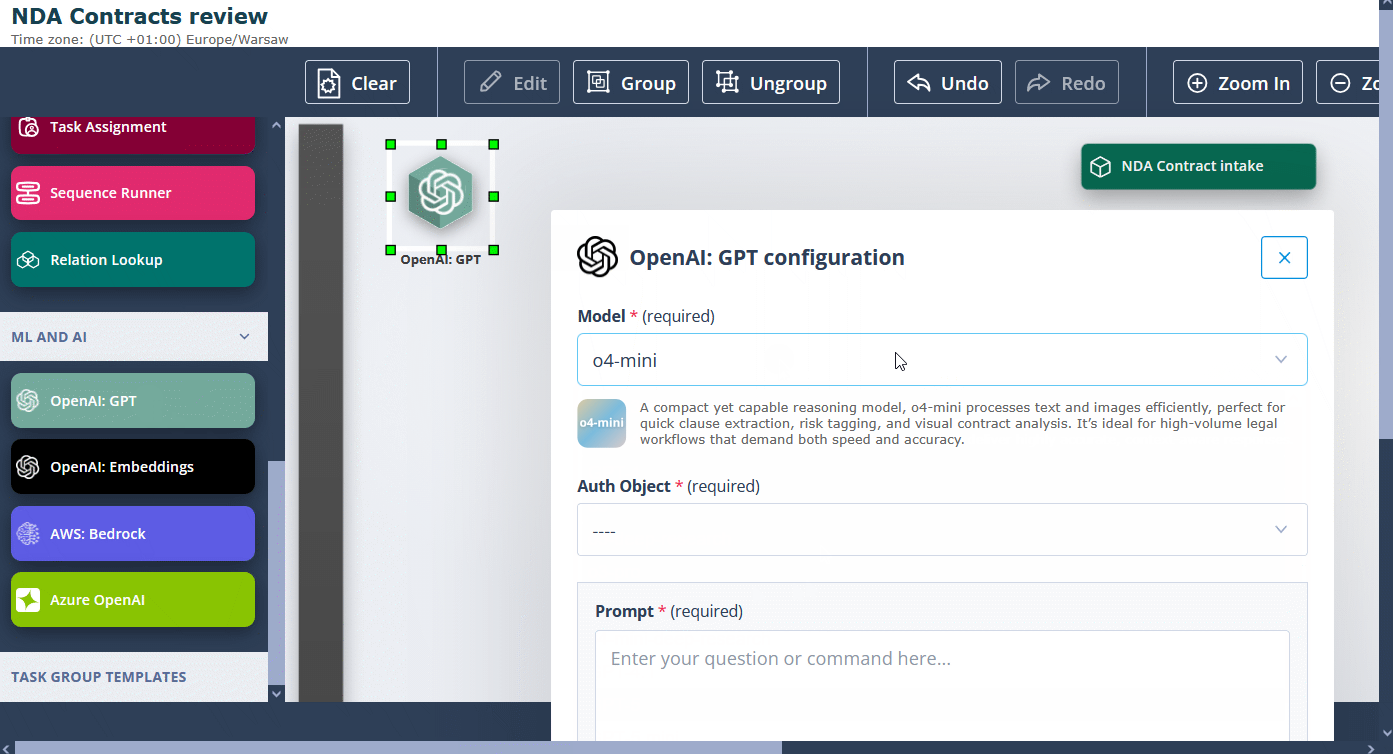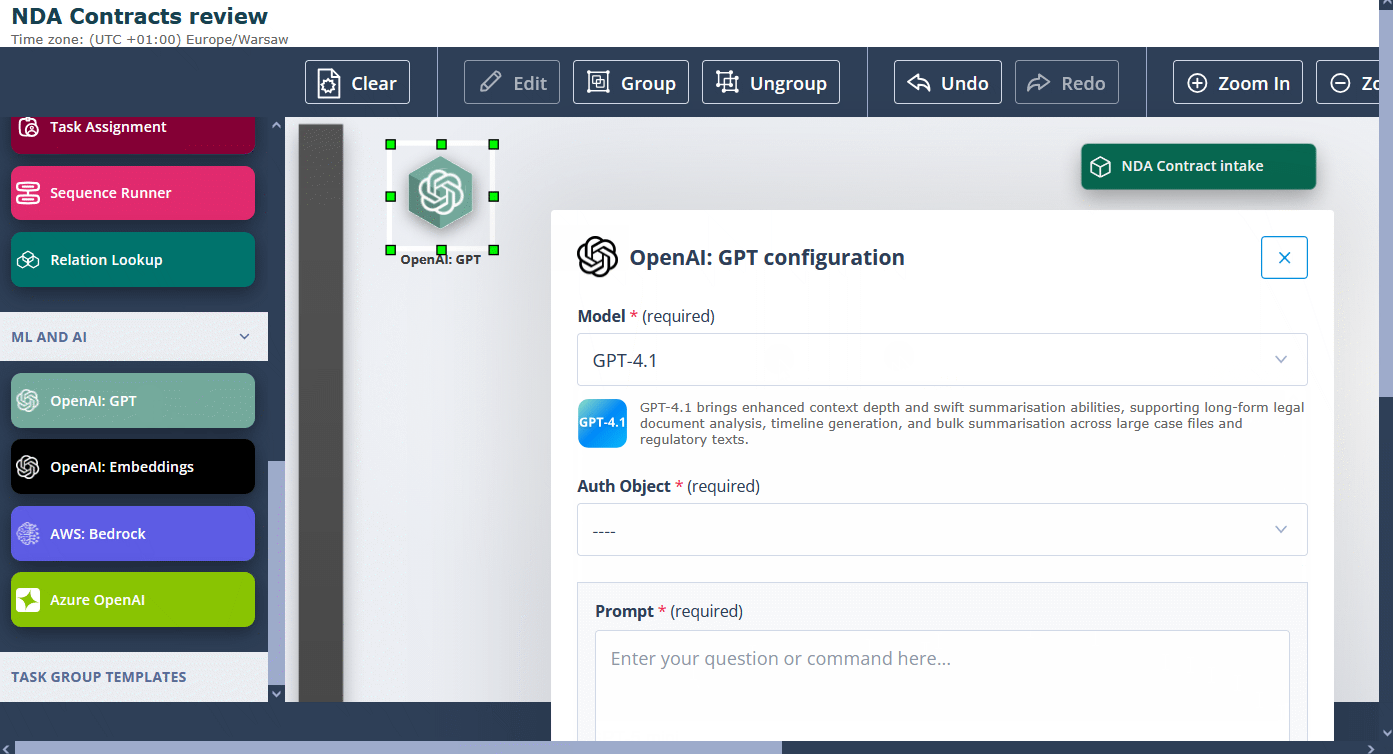
Separately, the OpenAI: GPT actor has been extended with the latest GPT family models, so you can keep using the OpenAI stack directly inside Sequencer.
New additions include:
- o3 family (o3, o3-deep-research, o3-pro)
- o4-mini and its deep-research variant
- GPT-4.1
- GPT-5 family (GPT-5, GPT-5 mini, GPT-5 nano)
These options give you a clear trade-off ladder: lighter models for high-throughput prompts and prototypes, fuller models for nuanced drafting, and deep-research variants where extra factual recall or creativity is needed.
On the Catalyst, that means you can, for example, call a compact o4-mini for quick clause normalisation across many records, then escalate a subset to GPT-4.1 or GPT-5 for polished client-facing summaries or legal drafting.
How this affects real workflows
Think of a typical due diligence pipeline: incoming vendor contracts are bulk-ingested and automatically classified; documents with risky indemnities are flagged; priority files are summarised and routed to senior counsel; routine items are filed automatically and linked to the right matters.
With more models in the toolbox, you assign each step the most appropriate engine: cheaper, fast models for mass triage; richer, longer-context models for final review; and tie the outputs into the rest of your automation: record creation, task assignment, DocuSign or iManage actions, and audit logging.
Orchestration is where the gain is felt: you don’t need a single “one-size-fits-all” model. You build a sequenced flow that sends the right work to the right model and then continues the process without human handoffs unless review is required. That keeps turnaround times down and provides consistent, auditable outputs.
Picking the right model
Choose between capability and cost:
- Use larger, long-context models (Claude Sonnet, GPT-4.1 / GPT-5) where nuance, accuracy and multi-document context are vital, for example, drafting precedent clauses or extracting complex obligations from contracts.
- Use the new OSS models on Bedrock if you want the specific characteristics they offer and the convenience of Bedrock integration.
We keep standard controls available in Sequencer: select the model, set parameters like temperature or max tokens, and pick the Authentication Object to use for requests. As always, you should test a new model on a small sample of real inputs to confirm output style and accuracy before scaling it into production.
In summary: this update widens the palette for building applied AI into legal operations: more models, more price/performance choices, and more ways to embed machine-assisted reasoning and extraction into your established processes. Pick the right engine for each job, stitch them together in Sequencer, and keep the work moving with consistent, auditable results.